
@synchronized 的实现方式
Jun 8, 2017
@synchronized 可以保证多线程不会同时执行一段代码,做用类似于锁,但比直接使用锁更加方便直观,那么它究竟是如何实现的呢?
查看 @synchronized 的实现
新建文件 main.m :
1 | int main(int argc, const char * argv[]) { |
在终端打开当前目录查看 C++ 实现:
1 | clang -rewrite-objc main.m -o main.cpp |
打开 main.cpp 文件删除顶部不相关的代码只剩 main 方法后:
1 | int main(int argc, const char * argv[]) { |
基本上可以看到,代码主要的实现是
1 | objc_sync_enter() |
方法按照顺序总共做了这么几件事:
- 定义异常值
- 定义
_sync_obj指向用来加锁的对象,防止代码修改加锁对象的指向而造成objc_sync_enter()和objc_sync_exit()的入参不是一个对象 - 调用
objc_sync_enter() - 定义一个结构体,传入
_sync_obj,并在析构的时候执行objc_sync_exit() - 执行要保证被同步执行的代码
- 捕获处理异常
其中第4、5步是在 try 的作用域,所以当 5 之后就会析构结构体变量并执行objc_sync_exit()
objc_sync_enter() 和 objc_sync_exit()
所幸 runtime 是开源的,可以通过源码查看这两个函数的实现:
1 | int objc_sync_enter(id obj) |
可以看到 objc_sync_enter 函数的逻辑:
- 判断 token(用来加锁的对象)是否为空
- 不为空就通过
id2data函数拿到一个SyncData对象,并加锁 - 为空则调用空实现函数,可以用符号断点来捕获 token 为空的情况
objc_sync_exit 的逻辑同样很简单:通过 id2data 函数拿到一个 SyncData 对象,并解锁。
看到这里,已经很明确了,对于 @synchronized 的实现是根据 token 来获得一把锁,在代码前后分别指向加锁和释放锁的操作。
SyncData 和锁的维护
那如何通过 token 获取一把锁呢,换言之 token 和锁是怎么对应起来的呢?或者说它们之间的关系是如何维护的?
这里就要提到 SyncData 这个数据结构:
1 | typedef struct alignas(CacheLineSize) SyncData { |
SyncData 做为一个链表节点,存储了 token 本身和下一个节点的信息,id2data 函数获取的就是这个节点。
id2data 函数的大致逻辑为:
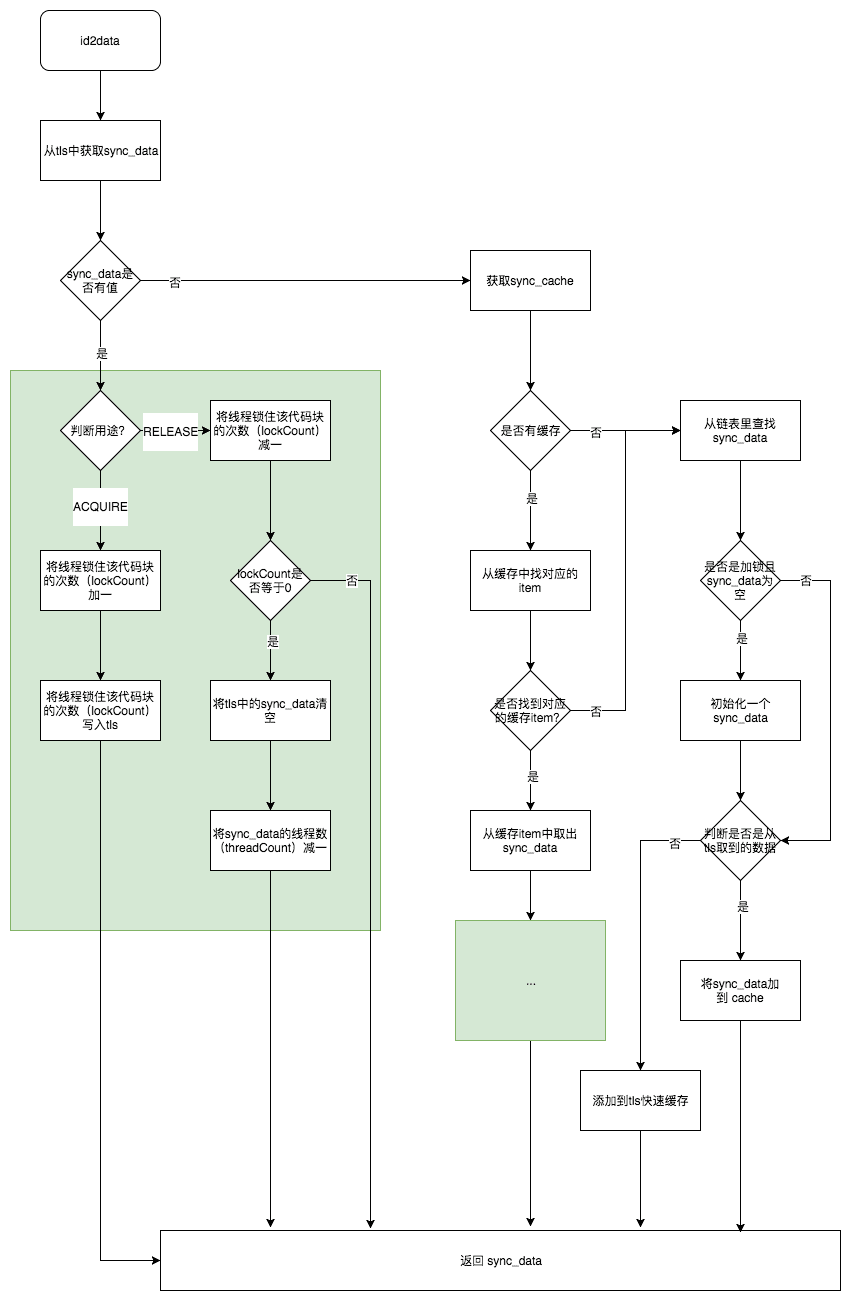
- 从 TLS(Thread Local Storage)中获取 SyncData 并返回
- 如果1没有获取到则从 SyncCache 获取
- 如果2仍然没有获取则从 StripedMap 获取一个链表,并从链表中查找
- 如果3没找到,则生成一个 SyncData
- 把找到或者生成的 SyncData 数据缓存至 TLS 或者 SyncCache
- 返回 SyncData
总结
@synchronized 的本质是根据 token 来获取一把锁,在编译的时候在需要保持同步的代码前后分别插入 objc_sync_enter() 和 objc_sync_exit() 函数。token 和 锁的映射数据是由一个哈希map来存储,key 是 token,value 是映射数据的链表。